
class="full-post-title">利用Mahout实现在Hadoop上运行K-Means算法
一、介绍Mahout
Mahout是Apache下的开源机器学习软件包,目前实现的机器学习算法主要包含有协同过滤/推荐引擎,聚类和分类三个部分。Mahout从设计开始就旨在建立可扩展的机器学习软件包,用于处理大数据机器学习的问题,当你正在研究的数据量大到不能在一台机器上运行时,就可以选择使用Mahout,让你的数据在Hadoop集群的进行分析。Mahout某些部分的实现直接创建在Hadoop之上,这就使得其具有进行大数据处理的能力,也是Mahout最大的优势所在。相比较于Weka,RapidMiner等图形化的机器学习软件,Mahout只提供机器学习的程序包(library),不提供用户图形界面,并且Mahout并不包含所有的机器学习算法实现,这一点可以算得上是她的一个劣势,但前面提到过Mahout并不是“又一个机器学习软件”,而是要成为一个“可扩展的用于处理大数据的机器学习软件”,但是我相信会有越来越多的机器学习算法会在Mahout上面实现。[1]
二、介绍K-Means
https://cwiki.apache.org/confluence/display/MAHOUT/K-Means+Clustering#,这是Apache官网上的算法描述,简单来说就是基于划分的聚类算法,把n个对象分为k个簇,以使簇内具有较高的相似度。相似度的计算根据一个簇中对象的平均值来进行。[2]
三、在Hadoop上实现运行
1,实验环境
①hadoop集群环境:1.2.1 一个Master,两个Slaves,在开始运行kmeans时启动hadoop
②操作系统:所有机器的系统均为ubuntu12.04
③Mahout版本:采用的是0.5版
2,数据准备
数据采用的是http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data,这是网上提供的一个比较不错是数据源。然后用指令 hadoop fs -put /home/hadoop/Desktop/data testdata,将在我桌面的文件data上传到HDFS的testdata目录下,这里为什么是testdata,我也正在思考,因为我本来是上传到input里,但是运行时提示could not find ….user/testdata之类的,所以现改为了testdata。
3,运行
①配置Mahout环境:在Apache官网下载Mahout的版本,我选择的是0.5,下载地址:https://cwiki.apache.org/confluence/display/MAHOUT/Downloads。然后解压到你指定的目录,将此目录路径写入/etc/profile,添加如下语句:
export MAHOUT_HOME=/home/hadoop/hadoop-1.2.1/mahout-distribution-0.5
export HADOOP_CONF_DIR=/home/hadoop/hadoop-1.2.1/conf
export PATH=$PATH:/home/hadoop/hadoop-1.2.1/bin:$MAHOUT_HOME/bin
然后执行 source /etc/profile。在mahout目录下执行bin/mahout命令,检测系统是否安装成功。如图:
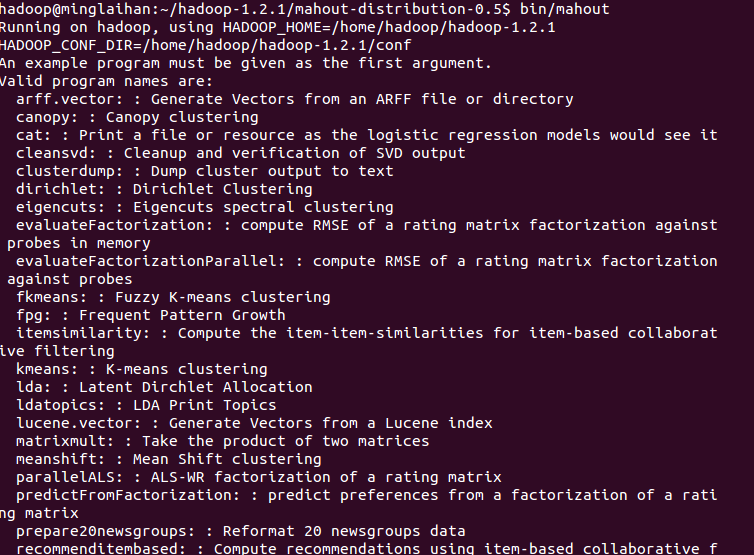
注:此处修改环境变量有些网上提示是/etc/bash.bashrc,我也试着修改过,但是发现在我这里使环境变量生效的是profile。
②运行Mahout里自带的K-Means算法,bin/mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job,这里启动后遇到了一点问题,提示Could not find math.vector,后来参考这篇http://jerrylead.iteye.com/blog/1188929日志解决。
4,结果
在我的环境下运行5分钟左右,最后生成一个文件,如图



相关推荐
mahout0.11版本,源码,可修改源码并自己编译,使用java语言编写,maven编译
#资源达人分享计划#
最新版本,在原先手动计算皮尔逊相似度和评分矩阵的基础上添加了Mahout实现的协同过滤推荐算法. 【备注】 主要针对计算机相关专业的正在做毕设的学生和需要项目实战的Java学习者。 也可作为课程设计、期末大作业。...
由于上传文件50M的限制,采用分卷压缩的形式,包括三个包:mahout-mahout-distribution-0.9.zip,distribution-0.9.z01,mahout-distribution-0.9.z02,mahout-distribution-0.9.z03,mahout-distribution-0.9.z04共...
由于上传文件50M的限制,采用分卷压缩的形式,包括三个包:mahout-mahout-distribution-0.9.zip,distribution-0.9.z01,mahout-distribution-0.9.z02,mahout-distribution-0.9.z03,mahout-distribution-0.9.z04共...
由于上传文件50M的限制,采用分卷压缩的形式,包括三个包:mahout-mahout-distribution-0.9.zip,distribution-0.9.z01,mahout-distribution-0.9.z02,mahout-distribution-0.9.z03,mahout-distribution-0.9.z04共...
基于Mahout实现协同过滤推荐算法的电影推荐系统
mahout是用来做大数据推荐系统和机器学习使用的框架,这个工具包官网下载非常慢,下载了一夜终于下载到了,刚好够上传的
Hadoop-Mahout 使用 Mahout 在 Hadoop 上进行推荐、集群和分类
完整版 上海财经大学MEM课程 大数据与云计算技术教程 大数据处理平台和技术 6-Mahout --- 大数据挖掘技术(共38页).pdf 完整版 上海财经大学MEM课程 大数据与云计算技术教程 大数据处理平台和技术 7- Hadoop其他...
mahout0.9的源码,支持hadoop2,需要自行使用mvn编译。mvn编译使用命令: mvn clean install -Dhadoop2 -Dhadoop.2.version=2.2.0 -DskipTests
mahout-examples-0.11.1 mahout-examples-0.11.1-job mahout-h2o_2.10-0.11.1 mahout-h2o_2.10-0.11.1-dependency-reduced mahout-hdfs-0.11.1 mahout-integration-0.11.1 mahout-math-0.11.1 mahout-math-0.11.1 ...
由于上传文件50M的限制,采用分卷压缩的形式,包括三个包:mahout-mahout-distribution-0.9.zip,distribution-0.9.z01,mahout-distribution-0.9.z02,mahout-distribution-0.9.z03,mahout-distribution-0.9.z04共...
由于上传文件50M的限制,采用分卷压缩的形式,包括三个包:mahout-mahout-distribution-0.9.zip,distribution-0.9.z01,mahout-distribution-0.9.z02,mahout-distribution-0.9.z03,mahout-distribution-0.9.z04共...
重新编译mahout-examples-0.9-job.jar,增加分类指标:最小最大精度、召回率。详情见http://blog.csdn.net/u012948976/article/details/50203249
MovieRecommender基于Mahout实现协同过滤推荐算法的电影推荐系统^
第二部分 功能主要包括四个方面:集群配置、集群算法监控、Hadoop模块、Mahout模块。 详情参考《Mahout算法调用展示平台2.1》
该资源是在Eclipse平台里,使用Mahout库的API,实现基于用户的协同过滤算法,从而进行商品推荐。 软件环境是:win7 64位 +Eclipse4.4 + jdk1.6, 用到了7个.jar包, 分别为:commons-logging-1.2.jar, commons-...
mahout-integration-0.7mahout-integration-0.7mahout-integration-0.7mahout-integration-0.7
基于Mahout协同过滤实现图书推荐系统_书籍推荐系统_源码